财联社5月28日讯,民生证券发布研报表示,英伟达近期迎来历史上最大单日涨幅,其核心的本质在于本次AI大模型带来划时代的变革已成共识。而算力的清晰路径逐步被大众认可,本质是在于最为确定的算力侧率先兑现:上游算力正处于进行时阶段,也为AI应用产品落地提供先决条件,AI下一演绎方向将着重于产品侧落地,平台生态巨头和垂直领域龙头具备产品落地的先决条件。
以下为原文:
1.1 英伟达业绩高增,算力需求持续验证
1.1.1 数据中心业务创新高带动英伟达业绩超预期
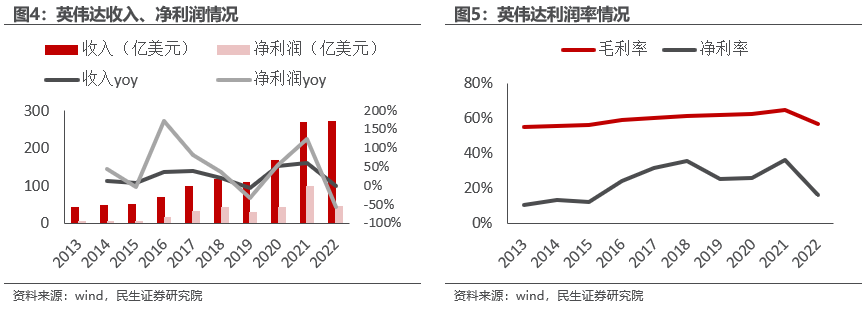
2023年5月25日,据英伟达官网、钛媒体数据,英伟达2023Q1实现营收71.92亿美元,同比减少13%,连续第二次减幅超10%,但高于公司指引区间、大幅优于分析师平均预期的65.2亿美元;非美国通用会计准则下净利润为27.13亿美元,同比下降21%,环比增长25%;毛利率为66.8%;每股收益1.09美元,高于分析师平均预期为0.92美元,同比下降20%,环比增长24%。由于业绩高于市场预期,加之英伟达预计二季度销售额110亿美元,同比增长64%。财报发布后的盘后交易中,英伟达股价大涨24.63%。
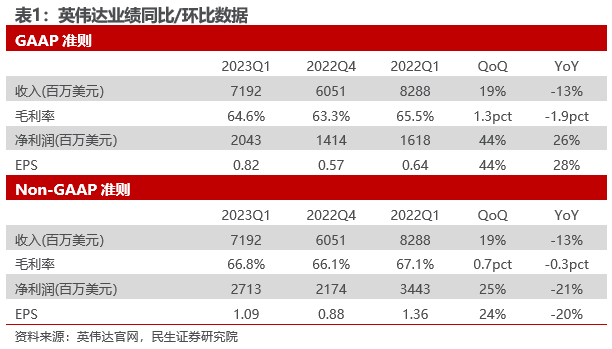
大模型AI快速发展带动数据中心业务创历史新高。英伟达2023Q1业绩超预期核心原因是数据中心业务营收达到创纪录的42.84亿美元,环比增长18%,同比增长14%。英伟达数据中心业务主要是云计算基础设施和算力芯片等,作为目前大模型训练、推理的关键算力资源,海内外各大科技巨头对算力的需求正在持续提升。据钛媒体,英伟达CFO克雷斯表示,目前市场对生成式 AI 芯片的需求超出先前评估,由于 AI 芯片需求仍保持强劲增长,英伟达给出乐观业绩预期。
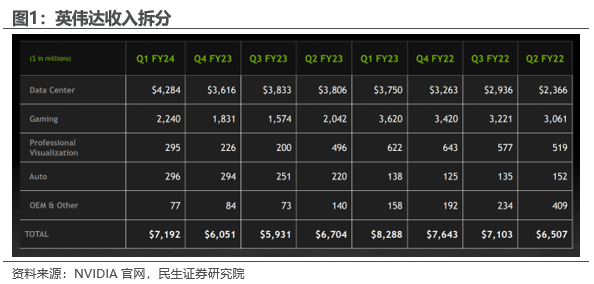
1.1.2 数据中心业务持续迭代带来强劲业绩指引
公司AI芯片等硬件基础设施持续升级。英伟达推出了NVIDIA Hopper? GPU架构、NVIDIA? H100 Tensor Core GPU以及第四代AI基础架构系统NVIDIA DGX? H100,这些新产品都在性能上实现了显著的提升。此外,公司还推出了基于Arm?的NVIDIA Grace? CPU Superchip,这是一种新的高速低延迟的芯片到芯片互联技术,两个CPU芯片能够直接进行高速数据交换,这比传统的互联方法更高效,可以大大减少数据在处理器之间传输的延迟,提供更高的性能,更低的能耗,以及更高效的处理大规模工作负载的能力。
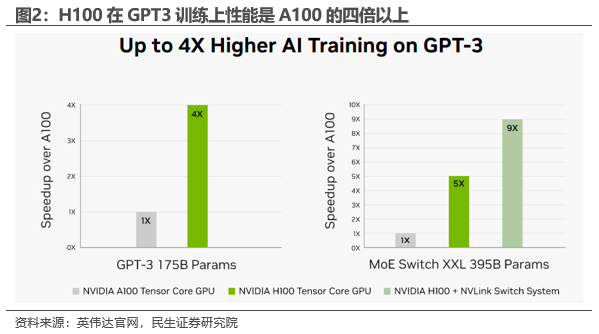
公司AI计算平台边界不断扩展。英伟达推出了NVIDIA Spectrum?-4,这是世界上首个400Gbps端到端的网络平台,为大规模的数据中心基础设施提供了极高的性能和强大的安全性。英伟达对其AI平台进行了重大更新,包括企业级软件和新的NVIDIA AI Accelerated程序,以提升AI应用的性能和可靠性。英伟达推出NVIDIA OVX?,这是一个专门的、可扩展的服务器参考设计,用于在Omniverse中创建工业级数字孪生;推出NVIDIA Clara? Holoscan MGX,这是一个专门为医疗设备行业设计的平台,用于开发和部署实时AI应用。
英伟达预计2024财年第二财季公司营收将达110亿美元,上下浮动2%,比去年同期67.0亿美元增长64%,而且比历史单季最高销售额还增长33%;毛利率预计达68.6%-70%之间,这一业绩展望远超分析师此前预期。
1.2 英伟达长期坚持GPU战略
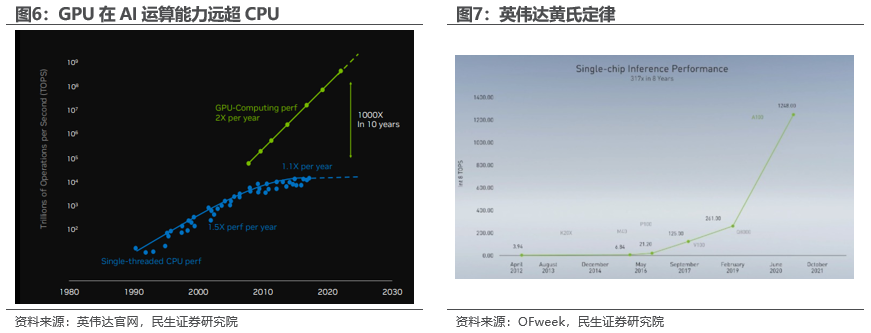
GPU接替CPU成为AI时代的底层算力。据沐曦集成电路,GPU的特点是并行处理能力强、计算能效比高,并且有很大的存储带宽。某些应用,在人工智能模型训练与推理、高性能计算等,往往是大数据流应用,这时,用GPGPU解决这类问题,就比CPU效率更高,它对于用传统语言编写的、软件形式的计算有较好的支持,具有高度的灵活性。英伟达创始人黄仁勋曾提出“摩尔定律已死”、黄氏定律(GPU性能一年翻一倍)等著名观点,坚持GPU芯片的战略。
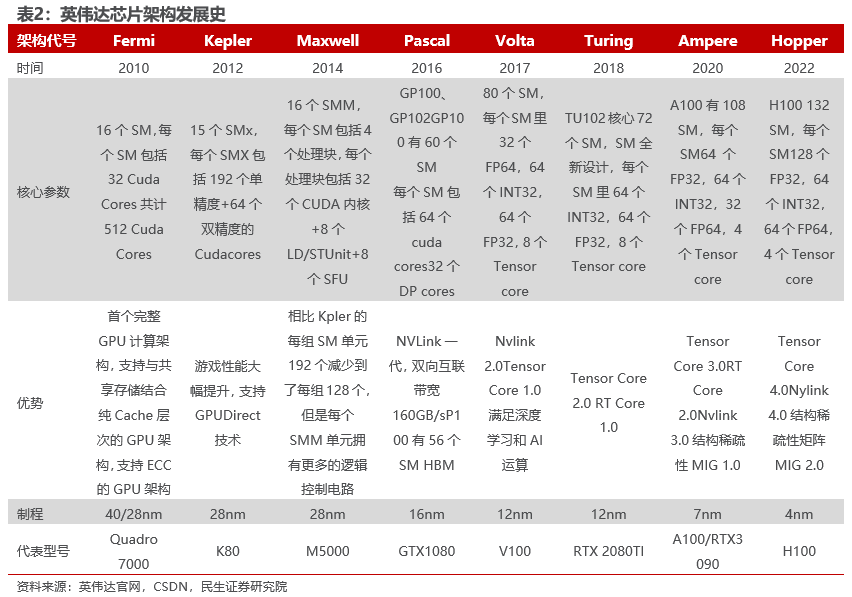
复盘历史,英伟达GPU一直是性能与功耗的最优解。据Twisted Meadows,英伟达每代芯片架构的 SM 都有较大设计改动,甚至有时连名字都改了(SMX、SMM),这是影响性能细节的关键;尽可能多的 SM 数和 Cache 容量是性能提升的核心要素,但是受限于芯片面积,厂商无法简单增加这两者。反而每隔几年的制程工艺提升总会带来 SM 和 Cache 的增加;SM 内的 FP32 数量曾在 Kepler 架构上被设计得很高,但是缓存不够大导致每个 FP32 能用的缓存很小,性能根本发挥不出来,所以 Nvidia 后来又逐渐调降了 SM 内 FP32 的数量;架构变迁中,英伟达在芯片面积有限、功耗/散热有限的情况下,不断调整各种组件的配置比例,凭借制程工艺的提升,不断寻找性能与功耗的最优解。
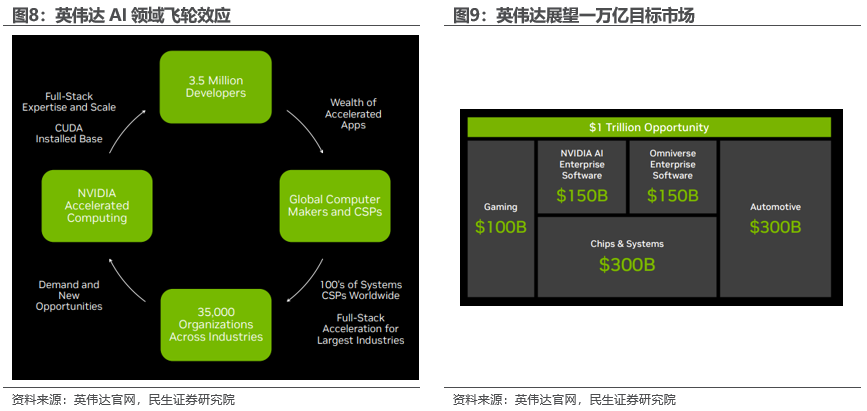
英伟达在AI领域创造飞轮效应,目标市场超万亿美元。英伟达AI领域飞轮效应体现在以下几个方面:
1)对于开发者,英伟达的统一架构和庞大的安装基础使得开发者的软件可以获得最佳性能和最广泛的覆盖。
2)对于电脑制造商和云服务提供商,英伟达丰富的加速平台套件让合作伙伴可以构建一个产品来应对包括媒体和娱乐、医疗、交通、能源、金融服务、制造业、零售等在内的大市场。
3)对于客户,英伟达的产品几乎可以在所有的计算提供商那里找到,并且能加速从云到边缘的最具影响力的应用。
4)对于英伟达自身,与开发者、计算提供商和来自不同行业的客户的深度互动使得英伟达在整个加速计算堆栈中拥有无与伦比的专业知识、规模和创新速度,进一步推动了飞轮效应的产生。
英伟达预计,当前未来全球数据中心等各类CPU应用场景都有望被GPU替代,英伟达拥有超万亿美元的目标市场。
1.3 微软谷歌等全球巨头纷纷入局,带来算力的清晰路径
海外巨头展开AI军备竞赛,算力强需求状态将维持甚至进一步提升。根据奇绩论坛,以2022年底ChatGPT出圈为起点,微软、谷歌、Meta以及众多AI独角兽迅速展开AI军备竞赛,AI算力严重供不应求,GPT停止账户申请和英伟达大涨都验证了算力的强需求。我们认为,当前已经十分强劲算力需求有望伴随高纬度多模态数据的训练以及海量的边缘AI推理的部署进而指数级提升。
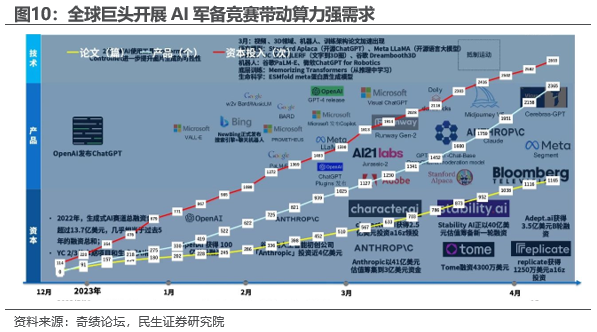
英伟达很难一家独大承担AI算力的所有需求, 以AMD为前瞻GPU其它供应商有望迎来转机。AMD作为英伟达的追赶者,产品硬件设计差距较小,在微软等巨头的强力支持下,AMD 较为薄弱的软件生态有望取得长足进步,AMD 将对英伟达形成强有力的挑战。
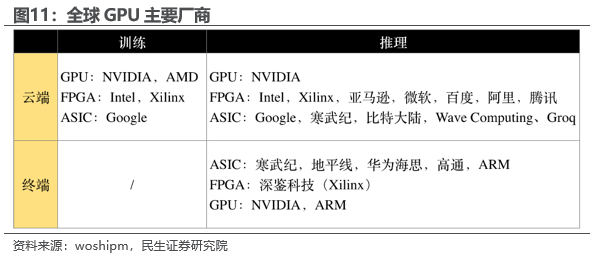
1.3.1 训练侧:高特征维度数据训练算力需求指数级增大
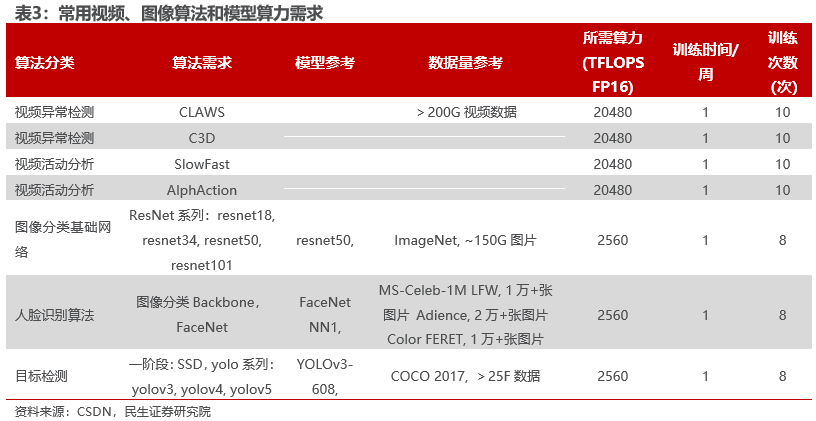
在大模型训练中,影响算力需求的主要因素有数据的信息密度和处理复杂度,算力需求随特征维度提升指数级提高。据CSDN,视频异常检测、视频活动分析等视频模型需要的算力是人脸识别、目标检测等图像模型算力需求的十倍。
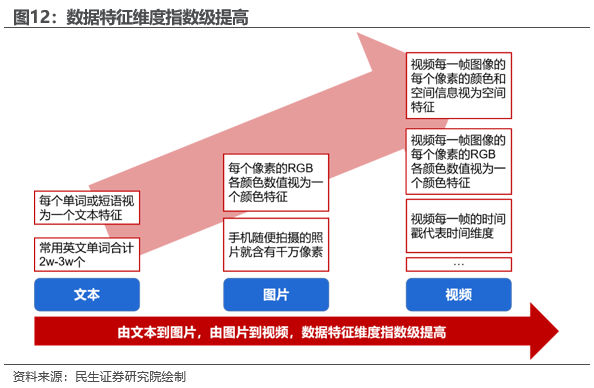
视频是高特征维度数据,拥有更高信息密度。视频的高特征维度主要来自于其丰富的信息内容,包括空间信息、时间信息、颜色信息、运动信息等:
空间信息:每一帧视频都是一个图像,包含了大量的空间信息。例如,一个1080p的视频帧包含1920×1080个像素,每个像素都有自己的颜色和亮度信息。因此,单帧视频的空间信息维度就是1920×1080=2073600。
时间信息:视频是由一系列的帧组成的,每一帧都是在一个特定的时间点捕捉的。因此,视频包含了大量的时间信息。例如,一个30秒的视频,帧率为30帧/秒,那么它包含了30×30=900帧。每一帧都有自己的时间戳,因此,视频的时间信息维度就是900。
颜色信息:每个像素都有自己的颜色信息,通常由红、绿、蓝三个通道的亮度值组成。因此,每个像素的颜色信息维度就是3。对于一个1080p的视频帧,颜色信息维度就是1920x1080x3=6220800。
运动信息:视频中的物体会随着时间的推移而移动,这种移动信息也是视频的一个重要特征。运动信息的维度很难直接量化,因为它取决于视频中物体的移动情况。
视频数据使用的模型需要进行大量矩阵运算等复杂运算,需要更高算力支持。文本生成通常使用的模型如RNN、LSTM等,其计算复杂度相对较低;图像生成通常使用的模型如CNN、GAN等,其计算复杂度比文本生成的模型高;视频生成通常使用的模型如3D-CNN、RNN+CNN等,其计算复杂度比图像生成的模型还要高,涉及卷积神经网络大量神经元间的矩阵运算。
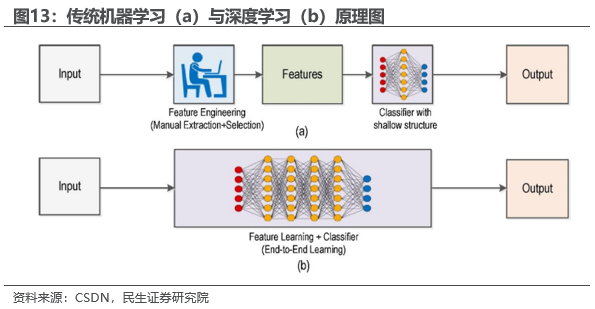
1.3.2 推理侧:边缘大模型AI推理将带来海量算力需求
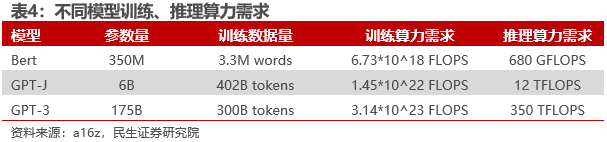
推理侧算力需求与边缘AI终端数量正相关。据数据猿,推理侧算力需求与模型规模(参数数量)、输入文本长度(问题长度)、输出文本长度(回复长度)以及模型的计算复杂性正相关,设备推理一次消耗的算力所需FLOPs ≈ L * D * N;其中,L是用户问题的输入长度与模型回答的输出长度之和,D是模型维度,N是模型层数。推理侧总体算力需求为所有设备推理算力的总和。据a16z,GPT3训练需要的总算力为3.14*10^23 FLOPs,而推理一次的算力需求为3.5*10^14 FLOPs,如果全球有一亿用户都推理一次,则推理算力需求超过训练算力需求。
大模型从云到端的趋势已经确定,解锁海量AI边缘推理所带来的算力需求。框架上,生成式AI由云向端的迈进成为大势所趋,谷歌和创达发布适用边缘的大模型,苹果将ChatGPT成功部署在苹果手机,英伟达推出具身智能AI大模型为机器人打开应用天花板;生态上,大模型作为AI时代的终极操作系统,ChatGPT超级APP只是第一步:移动端是当前刚需应用的主要载体,能够为大模型带来海量交互数据,大模型一方面与传统生态融合,创达推出与大模型结合的智能云、智能硬件、智能行业等最新解决方案。谷歌将AI全面融入搜索、邮箱、办公等全系列产品;另一方面,边缘AI全新应用生态有望不断落地,科大讯飞(002230)发布AI学习机和办公本等全系产品、英伟达发布具身智能机器人雏形是有力证明。此外,终端应用生态满足了具身智能训练中AI与周边的人与环境充分交互的需求,是具身智能AI落地的重要基础。
1.3.3 AMD:软件生态是主要短板正在不断追赶
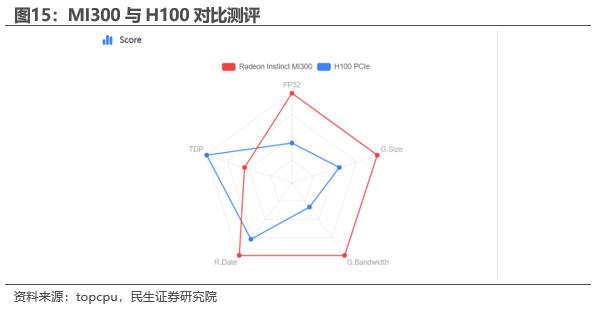
据TOPCPU测评,AMD最新MI300算力芯片纯硬件性能未必弱于英伟达H100,但英伟达以Tensor RT+CUDA的软件生态仍然是难以逾越的护城河。2023年CES 2023展会上AMD发布的MI300拥有13个小芯片,基于3D堆叠,包括24个Zen4 CPU内核,同时融合了CDNA 3和8个HBM3显存堆栈,集成了5nm和6nm IP,总共包含128GB HBM3显存和1460亿晶体管,据topcpu测评数据,纯硬件上MI300与H100互有胜负,差距不明显。相比之下,英伟达在软件生态层面建立Tensor RT+CUDA护城河优势更为显著。AMD自研ROCm框架采用开源模式有望弯道超车:ROCm使得开发人员能够获得 AMD Infinity Hub 交钥匙人工智能框架容器、改进的工具、精简安装,并支持TensorFlow 和 PyTorch 等主要机器学习框架,以帮助用户加速人工智能工作负载。从优化的 MIOpen 库到全面的 MIVisionX 计算机视觉和机器智能库、实用程序和应用程序,AMD 与人工智能开放社区广泛合作,以促进和扩展机器和深度学习功能和优化,从而帮助扩大加速计算所适用的工作负载。
1.4 AI进入产品落地验证的新阶段
AI产业链分为上游算力基础设施、中游大模型和算法以及下游各类AI应用。AI的上游算力需求超预期有望带动整个AI产业链走向兑现的新阶段。
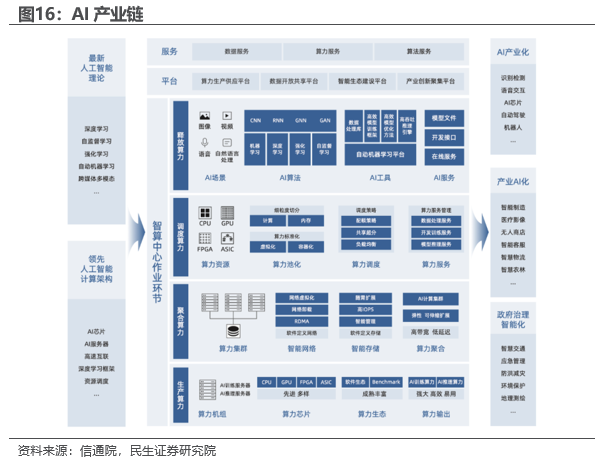
投资建议:英伟达近期迎来历史上最大单日涨幅,其核心的本质在于本次AI大模型带来划时代的变革已成共识。而算力的清晰路径逐步被大众认可,本质是在于最为确定的算力侧率先兑现:上游算力正处于进行时阶段,也为AI应用产品落地提供先决条件,AI下一演绎方向将着重于产品侧落地,平台生态巨头和垂直领域龙头具备产品落地的先决条件。在大模型蓄势待发的现阶段,作为行业龙头的相关企业天然具备自研大模型+高质量数据+产品的稀缺属性,建议关注中科创达(300496)、科大讯飞、金山办公、同花顺(300033)以及三六零(601360)。以海外算力龙头英伟达业绩超预期为前瞻,国内AI产业链上游需求有望得到验证,建议关注寒武纪、浪潮信息(000977)等。